XGBoost, LightGBM or CatBoost – which boosting algorithm should I use?
Gradient boosted trees have become the go-to algorithms when it comes to training on tabular data. Over the past couple of years, we’ve been fortunate to have not only one implementation of boosted trees, but several boosting algorithms– each with their own unique characteristics.
In this blog, we will try to determine whether there is one true killer algorithm that beats them all. We’ll compare XGBoost, LightGBM and CatBoost to the older GBM, measuring accuracy and speed on four fraud related datasets. We’ll also present a concise comparison among all new algorithms, allowing you to quickly understand the main differences between each. A prior understanding of gradient boosted trees is useful.

What’s their special thing?
The algorithms differ from one another in the implementation of the boosted trees algorithm and their technical compatibilities and limitations. XGBoost was the first to try improving GBM’s training time, followed by LightGBM and CatBoost, each with their own techniques, mostly related to the splitting mechanism. The packages of all algorithms are constantly being updated with more features and capabilities. In most cases, we present the default behavior of the algorithms in R, although other options may be available. In this section, we compare only XGBoost, LightGBM and CatBoost. If you miss GBM, don’t worry–you’ll find it in the results section.
A few important things to know before we dive into details:
Community strength – From our experience, XGBoost is the easiest to work with when you need to solve problems you encounter, because it has a strong community and many relevant community posts. LightGBM has a smaller community which makes it a bit harder to work with or use advanced features. CatBoost also has a small community, but they have a great Telegram channel where questions are answered by the package developers in a short time.
Analysis ease – When training a model, even if you work closely with the documentation, you want to make sure the training was performed exactly like you meant it to. For example, you want to make sure the right features were treated as categorical and that the trees were built correctly. With this criteria, I find CatBoost and LightGBM to be more of a blackbox, because it is not possible in R to plot the trees and to get all of the model’s information (it is not possible to get the model’s categorical features list, for example). XGBoost is more transparent, allowing easy plotting of trees and since it has no built-in categorical features encoding, there are no possible surprises related to features type.
Model serving limitations – When choosing your production algorithm, you can’t just conduct experiments in your favorite environment (R/Python) and choose the one with the best performance, because unfortunately, all algorithms have their limitations. For example, if you use a Predictive Model Markup Language (PMML) for scoring in production, it is available for all algorithms. However, in CatBoost you will have to encode categorical features by yourself because its encoding method cannot be converted to PMML. Hence, I recommend taking these considerations into account before starting to experiment with your own data.
Now let’s go over their main characteristics:
Splits
Catboost uses oblivious decision trees. Before learning, the possible values of each feature are divided into buckets delimited by threshold values, creating feature-split pairs. Example for such pairs are: (age, <5), (age, 5-10), (age, >10) and so on. In each level of an oblivious tree, the feature-split pair that brings to the lowest loss (according to a penalty function) is selected and is used for all the level’s nodes.
lightGBM uses gradient-based one-side sampling (GOSS) that selects the split using all the instances with large gradients (i.e., large error) and a random sample of instances with small gradients. In order to keep the same data distribution when computing the information gain, GOSS introduces a constant multiplier for the data instances with small gradients. Thus, GOSS achieves a good balance between increasing speed by reducing the number of data instances and keeping the accuracy for learned decision trees.
XGboost offers several methods for selecting the best split. For example, a histogram-based algorithm that buckets continuous features into discrete bins and uses these bins to find the split value in each node. This method is faster than the exact greedy algorithm, which linearly enumerates all the possible splits for continuous features, but it is slower compared to GOSS that is used by LightGBM.
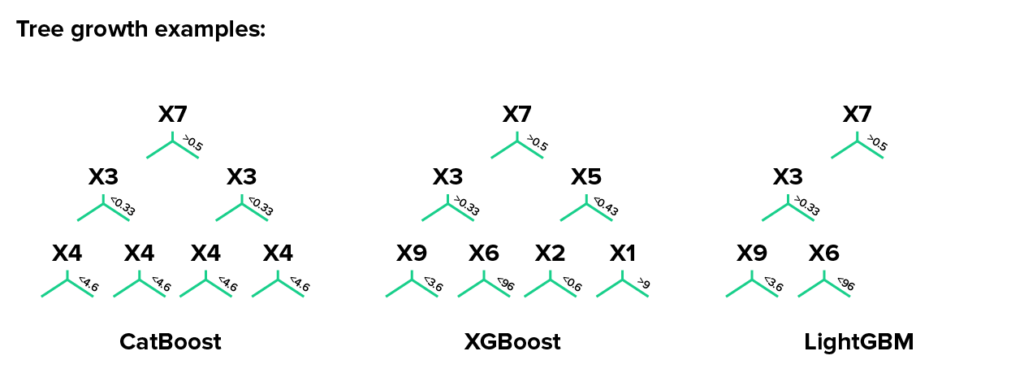
Leaf growth
Catboost grows a balanced tree.
LightGBM uses leaf-wise (best-first) tree growth. It chooses to grow the leaf that minimizes the loss, allowing a growth of an imbalanced tree. Because it doesn’t grow level-wise, but leaf-wise, overfitting can happen when data is small. In these cases, it is important to control the tree depth.
XGboost splits up to the specified max_depth hyperparameter and then starts pruning the tree backwards and removes splits beyond which there is no positive gain. It uses this approach since sometimes a split of no loss reduction may be followed by a split with loss reduction. XGBoost can also perform leaf-wise tree growth (as LightGBM).
Missing values handling
Catboost has two modes for processing missing values, “Min” and “Max”. In “Min”, missing values are processed as the minimum value for a feature (they are given a value that is less than all existing values). This way, it is guaranteed that a split that separates missing values from all other values is considered when selecting splits. “Max” works exactly the same as “Min”, only with maximum values.
In LightGBM and XGBoost missing values will be allocated to the side that reduces the loss in each split.
Feature importance methods
Catboost has two methods: The first is “PredictionValuesChange”. For each feature, PredictionValuesChange shows how much, on average, the prediction changes if the feature value changes. A feature would have a greater importance when a change in the feature value causes a big change in the predicted value. This is the default feature importance calculation method for non-ranking metrics. The second method is “LossFunctionChange”. This type of feature importance can be used for any model, but is particularly useful for ranking models. For each feature the value represents the difference between the loss value of the model with this feature and without it. Since it is computationally expensive to retrain the model without one of the features, this model is built approximately using the original model with this feature removed from all the trees in the ensemble. The calculation of this feature importance requires a dataset.
LightGBM and XGBoost have two similar methods: The first is “Gain” which is the improvement in accuracy (or total gain) brought by a feature to the branches it is on. The second method has a different name in each package: “split” (LightGBM) and “Frequency”/”Weight” (XGBoost). This method calculates the relative number of times a particular feature occurs in all splits of the model’s trees. This method can be biased by categorical features with a large number of categories.
XGBoost has one more method, “Coverage”, which is the relative number of observations related to a feature. For each feature, we count the number of observations used to decide the leaf node for.
Categorical features handling
Catboost uses a combination of one-hot encoding and an advanced mean encoding. For features with low number of categories, it uses one-hot encoding. The maximum number of categories for one-hot encoding can be controlled by the one_hot_max_size parameter. For the remaining categorical columns, CatBoost uses an efficient method of encoding, which is similar to mean encoding but with an additional mechanism aimed at reducing overfitting. Using CatBoost’s categorical encoding comes with a downside of a slower model. We won’t go into how exactly their encoding works, so for more details see CatBoost’s documentation.
LightGBM splits categorical features by partitioning their categories into 2 subsets. The basic idea is to sort the categories according to the training objective at each split. From our experience, this method does not necessarily improve the LightGBM model. It has comparable (and sometimes worse) performance than other methods (for example, target or label encoding).
XGBoost doesn’t have an inbuilt method for categorical features. Encoding (one-hot, target encoding, etc.) should be performed by the user.
Who is the winner?
We used 4 datasets in our experiment related to fraud prevention in the e-commerce world, with a binary target variable indicating whether an order made by a customer was fraudulent or legitimate. These example training datasets have around 300 features, a relatively high portion (~⅓) of categorical features and roughly 100K observations.
The metric we use is weighted AUC (WAUC), which is similar to AUC but allows the use of different weights to different classes. In our real world data, we have orders that were declined and we can only partially tag them. Therefore, we gave these orders a lower weight in the AUC calculation. Our adjusted metric will be further presented in a future blog.
In all experiments we trained on CPU, using an AWS c4.xlarge instance.
Training speed
We compared the training speed, attempting to create as similar as possible conditions to all algorithms. To do this, we trained a model with 4000 trees and a depth of 1 (root node only), with a learning rate of 0.01.
The plot below shows the results of the experiment. Each point represents the average of 3 repeated trainings.
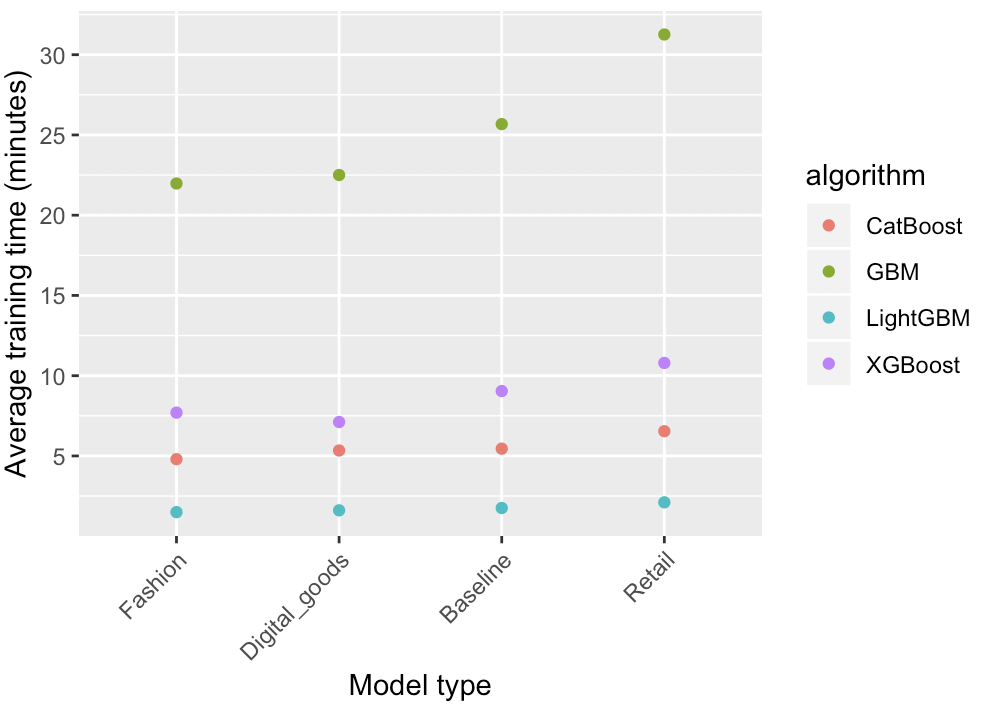
It is clear that LightGBM is the fastest out of all the other algorithms. CatBoost and XGBoost also present a meaningful improvement in comparison to GBM, but they are still behind LightGBM.
For our datasets, LightGBM, CatBoost and XGBoost were ~15x, 5x and 3x faster than GBM, respectively.
Accuracy comparison
We compared the algorithms’ WAUC on a test set after performing cross-validation hyperparameter tuning across the relevant algorithm’s parameters. We won’t get into the details regarding the chosen hyperparameters, but one thing worth mentioning is that the hyperparameters that were chosen for CatBoost resulted in a more complex model compared to the other algorithms, meaning that the final model almost always had a larger number of trees and a higher depth.
The table below shows the test results of the cross-validation experiment. Each cell represents the average WAUC of 5 repeated experiments.
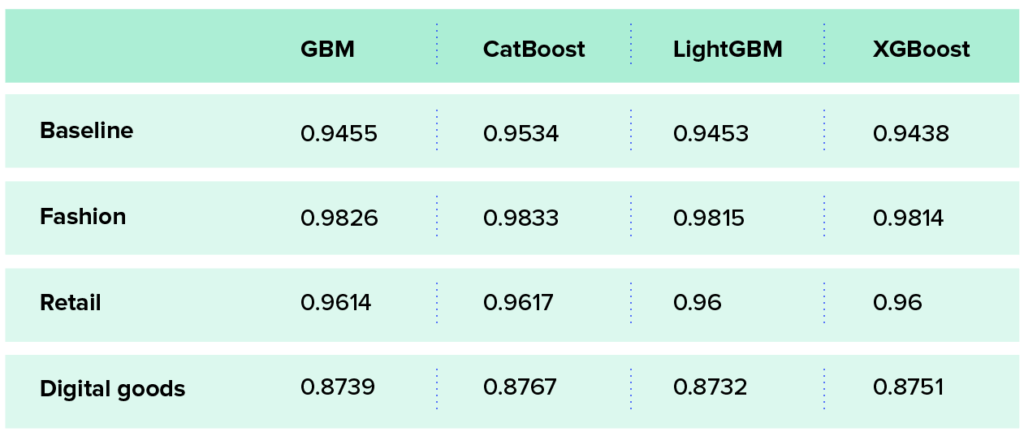
In the baseline dataset, CatBoost outperforms the rest by 0.8-1%, which is a meaningful difference. In the other datasets, the differences are not as significant, suggesting that accuracy might not be the main criterion when we choose an algorithm for these datasets. So, it’s important to take into account other criteria such as speed and technical limitations.
Endnotes
After working with all algorithms, we found that unfortunately there is no one winner across all criteria. Therefore, at Riskified, we chose to implement all of them in our systems and select the right one considering the relevant use-case. For example, if training speed is our pain point, we use LightGBM. In tasks where we need top accuracy, we may train all of the algorithms to find the one with the highest WAUC for that specific dataset.
On top of the work we presented here, there are other steps that can be taken for improving accuracy and speed. For improving speed, training on GPUs can be very meaningful. Another important step would be to tune a large number of hyperparameters. There are many hyperparameters that can be tuned in each package, some being exclusive to a specific algorithm. In one of our future blogs, we’ll present and compare tuning methods that can be used with boosting algorithms, such as three-phase search and Bayesian optimization. Stay tuned.
All packages are constantly being updated and improved, so we recommend following their releases, which sometimes include amazing new features.
Boost us with your comments, suggestions and thoughts!
Email: [email protected]
Twitter: Riskified